Data Visualization is a way to bring data to life. It’s a form of story-telling. It also is a great way to get a bigger picture of your data, especially big data.
The link leads you to a good infographic to learn more about different types of graphs.
Let’s look at the food reviews from Amazon.
# Install the pandas library
import pandas as pd
# Read the `amazon_fine_food_reviews` file in pandas
amazon_food = pd.read_csv("/depot/datamine/data/amazon/amazon_fine_food_reviews.csv")
# Print the first 5 lines to get some sense of the data
amazon_food.head()Output:
| ID | ProductId | UserID | ProfileName | HelpfulnessNumerator | HelpfulnessDenominator | Score | Time | Summary | Text |
|---|---|---|---|---|---|---|---|---|---|
1 |
B001E4KFG0 |
A3SGXH7AUHU8GW |
delmartian |
1 |
1 |
5 |
1303862400 |
Good Quality Dog Food |
I have bought several of the Vitality canned d… |
2 |
B00813GRG4 |
A1D87F6ZCVE5NK |
dll pa |
0 |
0 |
1 |
1346976000 |
Not as Advertised |
Product arrived labeled as Jumbo Salted Peanut… |
3 |
B000LQOCH0 |
ABXLMWJIXXAIN |
Natalia Corres "Natalia Corres" |
1 |
1 |
4 |
1219017600 |
"Delight" says it all |
This is a confection that has been around a fe… |
4 |
B000UA0QIQ |
A395BORC6FGVXV |
Karl |
3 |
3 |
2 |
1307923200 |
Cough Medicine |
If you are looking for the secret ingredient i… |
5 |
B006K2ZZ7K |
A1UQRSCLF8GW1T |
Michael D. Bigham "M. Wassir" |
0 |
0 |
5 |
1350777600 |
Great taffy |
Great taffy at a great price. There was a wid… |
We don’t want to read every single review in the Text column to get a better understanding what people feel about a particular product. It is time consuiming and inefficient.
Instead, we can generate a tag cloud that maps words where color, size, or font reflect the word’s importance. For example, bigger a word, more important the word is. A tag cloud is a good visual representation for textual data.
How many distinct products are there in the dataset?
# Unique count of products in the dataset
len(amazon_food['ProductId'].value_counts())Output: 74258
We have 74258 products in total, but if we run the code to find how many products only have one review,
# Find the number of products that only have one review
sum(amazon_food['ProductId'].value_counts()==1)Output: 30408
Note that in bool, True has an equivalent value of 1, and False has an equivalent value of 0.
We see that 30408 of the products only have one review, and wordclouds are highly unlikely to be helpful for those single reviewed products.
Pick a product ID with multiple reviews you’re interested in and create a subset.
For this example, I’ll use ID = 'B007JFMH8M'.
# Extract a smaller subset from the dataset specifically about ProductID B007JFMH8M and reset index
my_subset = amazon_food[amazon_food['ProductId']=='B007JFMH8M'].reset_index(drop=True)Before we generate a tag cloud, data wrangling is required.
Words like "are", "thing", and "that" aren’t very helpful and do not contribute to the data story. They are called stopwords. We want to remove all stopwords from the Amazon reviews.
We can easily receive a generalized list of stopwords from the library called wordcloud.
from wordcloud import STOPWORDS
print(STOPWORDS)Output:
{'having', 'few', 'further', 'him', 'have', 'i', 'were', 'who', 'why', 'below',
"don't", 'or', 'ever', 'themselves', 'whom', 'theirs', "there's", ... }
Note that those stopwords consist punctuation, and we cannot depend nor assume that humans who wrote Amazon reviews would write in perfect English grammar. So it’s a safer bet to remove all the puntuations in both stopwords and Amazon reviews to keep things consisten and also lowercase the reviews.
To remove puntuations from the stopwords, we can run something like this line of code.
import string
# Create a new list variable for stopwords with no punctuation
words = []
# for loop to go through every word in STOPWORDS set
for word in STOPWORDS:
# initialize empty string
new_word = ''
# for loop to go through every letter in a word
for letter in word:
# check if letter is not a punctuation
if letter not in string.punctuation:
# add the letter to new_word
new_word += letter
# add word with no punctuation to the list
words.append(new_word)The code above consists multiple lines and can be shortened to a line as shown below using a list comprehension.
import string
# performs the same thing as the code above except it's just a line of code
words = [''.join(letter for letter in word if letter not in string.punctuation) for word in STOPWORDS if word]Output: ['having', 'few', 'further', 'him', 'have', 'i', 'were', 'who', 'why', 'below', 'dont', 'or', 'ever', 'themselves', 'whom', 'theirs', 'theres', ...]
To remove any symbols and any funny-looking characters, we can use regular expression to keep alphanumeric characters only.
Python has a good documentation that gently introduces the usage of regular expression (re).
The replace function will search and replace a specific parameter in a string with another specific parameter.
We want to remove all non-alphanumeric characters (anything that is not a letter or number), and we can use the replace function to search for all non-alphanumeric characters in my_subset['Text'] replace them with an empty string.
Our regular expression is something like [^A-Za-z0-9 ] where
-
A-Za-zrepresents a set of the whole English alphabet (both uppercase and lowercase) -
0-9represents all numbers between 0 and 9.-
note that there’s a space after 'z'
-
-
^represents complement or exclusion
So the whole expression [^A-Za-z0-9 ] will search for all characters that does NOT check any of those requirements. Other words, the expression will search for any non-letter, non-number, and non-space.
Since we are using re, we need to add an argument in the replace function to let the function know that the input argument is in re form.
Then multiple loops are created to remove all the stopwords from all of the reviews as shown in the code snippet below.
# Search for all non-alphanumeric characters and replace them with an empty string
# regex=True to let the function knows that the input is in re form
reviews = my_subset['Text'].replace(r'[^A-Za-z0-9 ]', '', regex=True)
# for loop to go through every review
for index in range(0,len(reviews)):
# initialize empty string
new_string = ''
# for loop to go through every word in the string
for word in reviews[index].split():
# check if the word is not stopword
if word.lower() not in words:
# add the word with a space at the end
new_string += word.lower() + " "
# replace the old value with the new value
# without trailing space at the end
reviews[index] = new_string.rstrip()The code snippet above can be shortened into one line as shown below.
# performs the same thing as the code above except it's just a line of code
reviews = my_subset['Text'].replace(r'[^A-Za-z0-9 ]', '', regex=True).apply(lambda x: ' '.join([word.lower() for word in x.split() if word.lower() not in (words)]))Because the function, WordCloud, only accepts string format as argument, we can simply combine the whole Text column into a long string.
text = ' '.join(reviews)Yay, data cleaning is completed at this point! Now, we can easily make a tag map.
To generate a wordcloud map in Jupyter notebook, we simply can run this block of code.
# import required libraries
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# Feel free to modify the plot features
word_cloud = WordCloud(width=3000, height=2000, collocations = False, background_color = 'white').generate(text)
plt.figure( figsize=(20,10),facecolor='k')
plt.imshow(word_cloud, interpolation='bilinear')
plt.tight_layout(pad=0)
plt.axis("off")
plt.show()If you follow the steps exactly, you should get this output as the result.
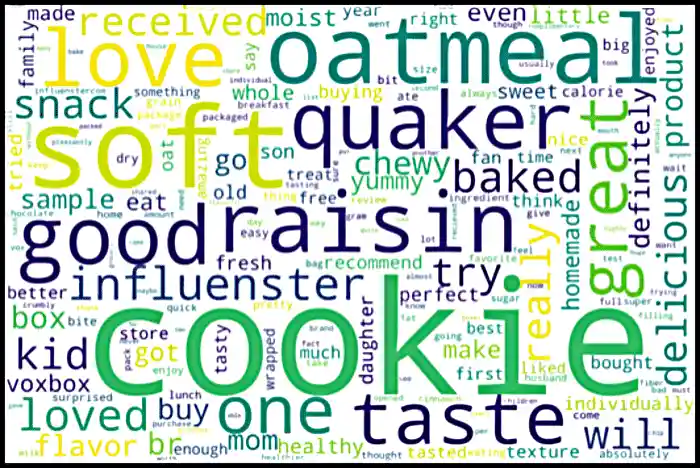
|
It’s so important to recognize the limitations of any visualization. Often, when transforming data into a visual aid, it omits some details and can be misleading. For this case with wordclouds, textual data is hard to work with because humans write in multiple different styles. For example, the two sentences, "do not like chocolate" and "dislike chocolate," have similar meanings. If we run those sentences through our data cleaning process, we’ll have something like "like chocolate" and "dislike chocolate" as our results, and now they have two different meanings. If we aren’t careful with our textual data, misunderstandings and misleading information can lead more chaos. Furthermore, this choice of visualization may be inaccessible for some people. |